




This will make your life easier. If you’re not in the mood to read something very technical and practical, save it. Mark this page for later. You’ll be glad you did, especially if your goal is to develop large, scalable, efficient, functional, and incredibly fast databases on your own.
There are two key ways to develop these types of databases with MongoDB. But first, you have to examine your queries.
How do I identify “slow queries”?
I recently answered this question in a workshop for my colleagues at BEON. Their eyes were glued to the screen, especially when I explained that you only need to follow these three steps to know if your query is slow:
Use the .explain() command.
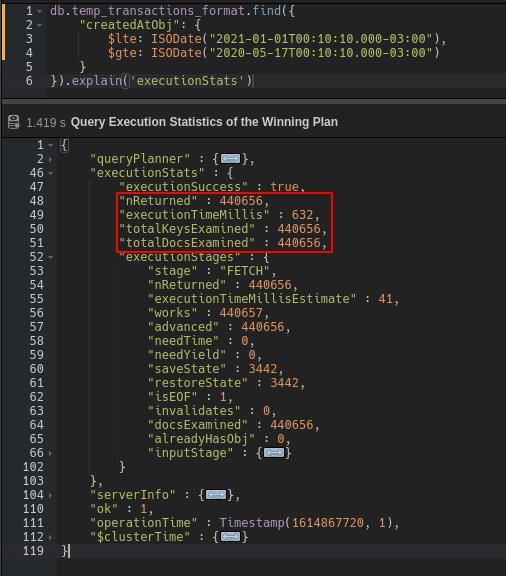
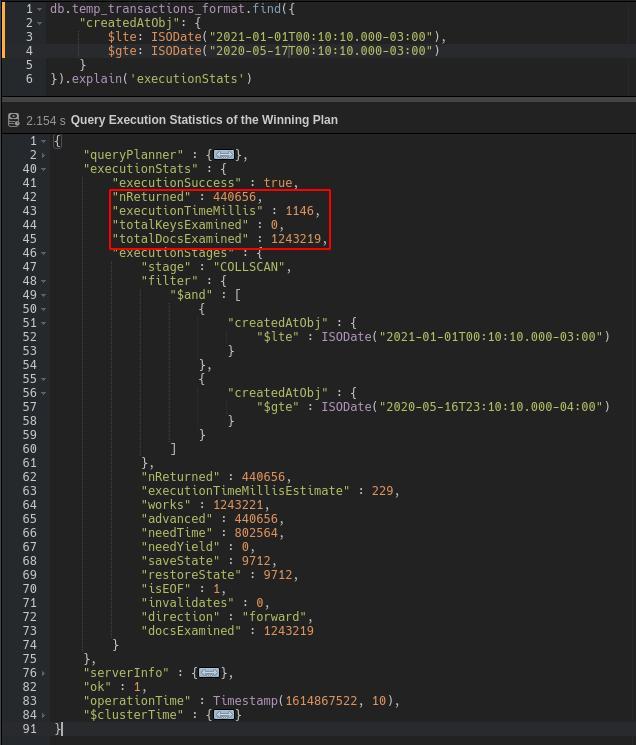
Doing so helps you analyze the key points of query performance. This function supports different values but, for now, let’s focus on “executionStats,” which adds statistics to the result.
Check if the collection is scanned each time the query is executed.
Once the results of the .explain(‘executionStats’) are deployed, check the different stages performed by the query. If the result is “COLLSCAN,” it means the collection was scanned, while the result “IXSCAN” implies that only the index keys were. Scanning the entire collection is extremely inefficient and can greatly slow query performance.
View the number of docs scanned versus docs returned.
The nReturned field describes the number of documents returned while TotalDocsExamined describes the number of documents scanned during the query. If the number of docs scanned is much larger than the number of docs returned, the query is not efficiently searching for the documents in the collection. The number of scanned documents should be as close to the number of returned docs as possible.
Bonus: cloud database services.
In addition to the previous three steps, you can analyze many more aspects of your database performance with the help of a CDS like MongoDB Atlas, which helps you visualize performance with accurate graphics, even in real time, showing execution times, process CPUs, and more since query performance also depends on the performance of the instance where the database is.
How’d it go? Did you find several areas to improve? Even in the worst cases, there are many things you can do to turn the situation around and achieve highly efficient performance.
If you think your queries are performing poorly, this series of simple steps will help you improve.
Mongodb atlas create index—how to do it
“Efficiency is doing better what is already being done. Effectiveness is deciding what to do better.” – Peter F. Drucker
Many ask about the Mongodb atlas create index, because indexes are easy-to-read data structures with collection information, serving as a map for searching for documents, saved in RAM before disk. Indexes can be reused depending on their values.
In MongoDB atlas, to create an index, you only have to implement the db.collectionname.createIndex(-“example_key”: 1-) or db.collectionname.createIndex(-“example_key”: -1-) command if you want your index to be negative. The difference between negative and positive is in the order in which the indexes are stored.
The workshop I gave about MongoDB was quick. However, my colleagues and I continued to talk about various MongoDB Atlas tools well after it ended, including the Performance Advisor. This tool has the option to scan operations and identify the most appropriate indexes you can create, improving performance up to 10% with each MongoDB atlas create index. Needless to say, it’s very useful.
Indexes consume space. They are updated by modifying the source code. So, if the indexed field is never used and must always be updated, it defeats the purpose of improving performance, consumes memory, and becomes an obstacle. Please keep this in mind when dealing with Mongo atlas create index.
How to use the extended reference pattern
Sometimes it makes sense to have separate data collections. If you can think of an entity as a unique “thing,” it makes sense to separate it. For example, in an e-commerce app, there are orders, customers, and an inventory. They are separate logical entities.
But, from a performance point of view, this arrangement is problematic. For example, a customer can have N orders, creating a 1-N relationship. But from the point of view of each order, there is an N-1 relationship with the customer, so a transaction with many orders needs several JOIN operations that slow down the process (either by using the “aggregate” method or by making separate queries). Attempting to embed all the data about a customer in each order isn’t a good option either, as it generates a large amount of duplicated information. Also, you may not need all customer information for an order.
The extended reference pattern provides a great way to handle these situations. Instead of embedding all customer data or adding a reference, you can copy only the fields you access frequently or those that have the highest priority, such as name and address.
An extended reference has the following benefits:
- Decreases the amount of JOINs in queries
- Enhances performance by not requiring extra searches
- Allows you to use indexes for extra fields, which would be more difficult if you used JOIN
But since you’re duplicating the data, it can be difficult to maintain this pattern, and it could lead to inconsistencies. Therefore, the extended pattern works best if the data stored in the document are fields that change infrequently. Something like one person’s ID and name are good options (without leaving out the document reference in the other collection) because they rarely change.
The best way to approach it is to incorporate and duplicate only the necessary data. Think about an order invoice. If you include the customer’s phone number, do you need their secondary phone number? Probably not, so you can leave that data out of the invoice collection.
Let’s get to work!
As we’ve seen, to optimize MongoDB performance, you need to analyze queries through tools like the .explain command and cloud services like MongoDB Atlas. Then you can implement best practices such as using indexes and the most optimal pattern for data. Sure, with MondoDB atlas, create index and extended patterns for every situation is impossible, but I think it’s worth doing where possible. As you can see for yourself, the advantages are undeniable.
Good luck!
Explore our

What I Learned on December 23, 2020
We felt the satisfaction that comes from knowing that, despite everything that happened during this challenging year, we were there, together. ..

The Challenges of Deploying Real-Time Streaming Platforms
Have you heard the saying, “Whatever you do, do it right”? Doing things right isn’t always easy, but it’s always worth the effort. ..

Why 2020 Was Our Best Year So Far
Facing these circumstances has taught us something we will never forget. ..