

A lot is being said about Machine Learning. However, as much as Machine Learning is thought to be one of the 21st century’s most important achievements (even if everything actually started in the early 20th century), by many, even tech experts, it still looks like fruit that is hanging in the top of the tree, too far away from their arms to reach out to.
Machine Learning and AI are more than core skills, which means that they are not exclusive skills to a Data Scientist or Machine Learning Engineer. Rather, I’d say that Machine Learning is a skill in reach to any developer. I like to compare Machine Learning to Infrastructure as a Code and Data Pipelines.
While these are rarely requirements for a developer job, knowing them is always a plus, as they can reduce the friction between a developer and the specialist team, such as the SRE and Data Engineering Team. But differently to these skills, I’d argue that knowing Machine Learning fundamentals can also give a developer an edge in identifying business opportunities and growing their position in any organization. That’s why keeping up to date with technology-oriented blogs like DesignRush is always a good idea.

With that in mind, the main question for a developer reading this article probably is: Where should I start, then?
The Most Frequently Asked Questions About Machine Learning
Machine Learning relates to algorithms and techniques to allow a computer to learn from inputs and produce the desired outputs. Imagine if you could just provide a function with its inputs and it would automatically design its internal logic so that it provides the expected output. That’s the basic concept of Machine Learning. This is basically what Alan Turing said in his initial thoughts on Machine Learning in 1950, see:
We may hope that machines will eventually compete with men in all purely intellectual fields. But which are the best ones to start with? Even this is a difficult decision. Many people think that a very abstract activity, like the playing of chess, would be best. It can also be maintained that it is best to provide the machine with the best sense organs that money can buy, and then teach it to understand and speak English. This process could follow the normal teaching of a child. Things would be pointed out and named, etc. Again I do not know what the right answer is, but I think both approaches should be tried.
Alan M. Turing, 1950

What is Artificial Intelligence to Machine Learning?
That would be a bigger field, a superset that includes Machine Learning and other areas/techniques. It could be argued that Machine Learning is one of the currently most accessible and well-developed ways to do (partial) AI.
Why let the Machine Learn by itself, if we can program it?
For many reasons—it’s hard, takes time, and is prone to error. Imagine creating an if-else/switch statement to account for thirty different input parameters and take a different decision based on each. Besides, computers are known for being great at following instructions (the statements) but bad at adapting. Machine Learning is an attempt to change that.
What is the relationship between Machine Learning and Deep Learning?
Deep Learning is a way to do Machine Learning using an algorithm called Neural networks—it’s called deep because they usually include many layers between the entry point and output of such networks.
Now, before talking more about algorithms, problems, and techniques in Machine Learning, we should talk about Data concepts, as today’s Machine Learning is mostly data-oriented.
Data Concepts Every Developer Must Know
When talking about Machine Learning, you’ll see a lot of data-related concepts, as training a machine learning algorithm requires data. The idea is to use data with specific algorithms to make them learn by doing the computational equivalent to “pointing out and naming”.

Before taking into the concepts, it should be pointed out that there are different types of data formats that can be used. The simpler is tabular data – you could imagine this one as the traditional database table – this is also called “Structured data”. Now, there’s also what is called “Unstructured data”, which could be plain text, images, etc. Usually, if your data is properly structured, you can apply machine learning on it directly. For unstructured data, you probably have to apply other tasks beforehand (like extracting topics, vectorizing inputs, convolute images, etc).
Quick summary of the most common and important data concepts
- Dataset: It’s the set of data that share similar characteristics that are used to train a Machine Learning model. Tabular data, texts, images, sound waves, etc.
- Predictive parameters (the famous X): the part of the dataset that you know and you’ll use as input to teach, test, or use a Machine Learning Algorithm. The input of a function.
- Target (y): The information that you actually want the Machine Learning Algorithm to get to. The output of a function. You can pass it as part of the training process in a supervised method (more on this later) or it can just be your final output.
- Weights (w): Some algorithms “train” internal weights to produce the expected output based on the input data. Some other algorithms use different concepts.
- Hyperparameters: These are algorithm-specific variables that can be tuned. It is not actually data related, but it can be used to tweak your training process. Terms like “learning rate” and “alpha” fit in this category.
- Labeled Data: when you have a dataset where you get both the Xs and the corresponding true ys so you can do supervised learning.
- Baseline: an important, however usually forgotten concept. It’s the default result that you would get if you applied the simplest/dumbest solution (more on this in validation).
- Training Set: the part of your entire dataset used for, surprise, train your data!
- Test Set: the part that is set aside for just testing the results from the training process. Not used during the learning process, but can be used during iterations to tweak hyperparameters.
- Validation Set: Only a few people use it, but is good practice to separate a small set of data for the final validation of your model. The difference is that you never use the Validation set to tweak hyperparameters.
- Model: The name of a trained Machine learning algorithm. Can also be used to refer to a specific machine learning (deep learning) architecture, which is in turn a set of interconnected algorithms.
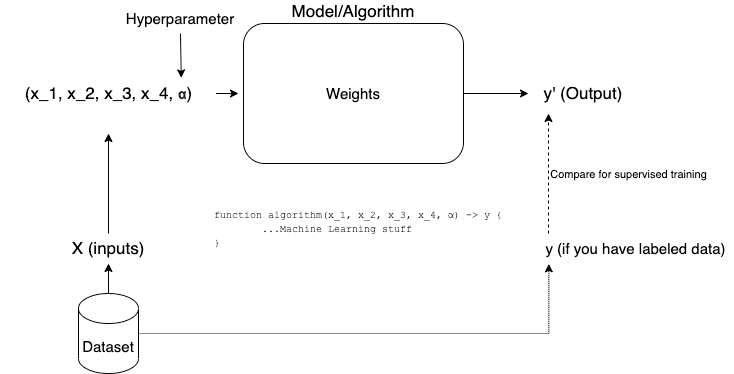
Now that we touched on relevant Data Concepts, the next step is to learn the most common methods of doing Machine Learning.
The Most Popular Machine Learning Methods
Usually, Machine Learning is done through two common methods—while the remaining are usually adaptations of the main methods. These two methods are Supervised Learning and Unsupervised Learning.
- Supervised Learning: is the method where you provide the algorithms with inputs and the correct outputs. The algorithm would be corrected based on the positive/negative responses from the outputs. The way this learning process happens varies a lot depending on the algorithm used, but the methodology is similar as you provide X and the correctly.
- Unsupervised Learning: is the method where you don’t have Labeled Data available (or you don’t trust it). In this case, you have to define a metric that your algorithm should optimize to. This metric can be a fictional distance between two points or any other kind of value.
Other frequently mentioned Methods are Semi-supervised learning, where there’s a combination of Supervised and Unsupervised methods (used when there’s a lack of annotated data); Active learning, where the model “queries” the user for improving confidence in the answer; and Self-supervised learning, where an algorithm is created to provide synthetic labels to unlabeled data.


Most Common Machine Learning Problems and Their Solutions
Besides the different methods, there are also different problems. If the way to use the available data to train a model is the main differentiator for choosing Machine Learning Methods, in the Machine Learning Problems what changes is the objective of the model.
There are many different types of problems. But we’ll present three: Classification, Regression, and Clustering.
Classification – is when you want to define what type of class a data entry belongs to. Example: given the readings of a set of sensors, the model decides if the machine is about to break or not.

Regression – is when you want to define a continuous value that a data entry belongs to. Example: what is going to be the industrial oven temperature if we configure its inputs and content in a specific way.

Clustering – is when you want to find clusters or groups of similar entries. Example: you have a dataset with data about user sessions and you want to group your users based on usage patterns, maybe for marketing purposes.
Evaluating Machine Learning Models
This is usually considered a tricky part, as there are many different methods of evaluating an algorithm. For the sake of simplicity, we’ll focus on binary classification and regression evaluation, but you can always research specific techniques for clustering, multi-class classification, and other problems.
Before moving on, one thing should be clear: to evaluate a model properly, you need to have an understanding of the data being used.
Evaluating a Binary Classification Problem

Accuracy Of Results In A Machine Learning Model
The most obvious way to evaluate a Machine Learning Model. Mostly used for Classification problems. It is very straightforward: how many of the entries were correctly classified.
However, accuracy has a few major flaws: 1) If your dataset is unbalanced (you have 90% of A-Class entries and 10% of B-Class entries), it won’t actually be a real representative of “how good” your algorithm is (if it randomly guesses everything to be A, it will be correct 90% of the time, but won’t be doing anything useful).
There enter 4 important concepts related to the truth value of a solution:
- True Positive: when an algorithm correctly identifies something. GOOD
- The patient was sick and it was identified that he was sick.
- False Positive: when an algorithm incorrectly identifies something. BAD
- The patient was not sick and it was identified that he was sick.
- True Negative: when an algorithm correctly does not identify something. GOOD
- The patient was not sick and it was identified that he was not sick.
- False Negative: when an algorithm incorrectly does not identify something. BAD
- The patient was sick and it was identified that he was not sick.
Here we can see that there are two ways it can be correct and two ways it can be incorrect. Accuracy only accounts for True Positives.
Other metrics allow better results in evaluating Machine Learning Results
Precision – Evaluates how many true and false positives were actually true positives. It shows how precise an algorithm is at reaching correct answers.
Recall – Evaluates how many of true positives and false negatives were actually true positives. It shows how good the algorithm is at getting relevant results.
F1 – The harmonic mean of Precision and Recall – it helps to get the best of both precision and recall.
The good thing about Precision+Recall and F1 is that it will give bad scores for a random guesser, as there will be a lot of false positives.
Evaluating a Regression Problem.
On regression problems, you don’t have a true/false value. You get continuous values. Therefore, you can’t compare if it was a precise hit. The solution is to compute the difference between the expected result and the result that the algorithm gave you.
Then, the goal is to minimize this error as much as possible. There are different ways to do the math for this, such as R Square, Root Mean Square Error (RMSE), and Mean Absolute Error (MAE), with slightly different applications. Always check which fits you the most.
Conclusion
In this article, we’ve provided a developer-friendly overview of the most important concepts in Machine Learning. The objective was not to make you an expert of Machine Learning, but rather present the most important concepts and warnings so you can start to identify opportunities and work with machine learning in your developer jobs. This technique can be applied to any area of software development, including software architecture, for which I’d recommend a reading on how buildings learn, if you’re interested 😉
If you approach machine learning with open arms, you’ll realize that anyone can enter this fascinating industry and move along society as new technologies shape the world around us.
